Apple's 'Illusion of Thinking' paper is not so puzzling

Recent research from Apple uses puzzles to explore LLM based reasoning and claims that AI “thinking” is an illusion. They found that these models collapse at certain complexity thresholds. Meanwhile recent work from Anthropic also showed that LLM chain-of-thought explanations often hide what they’re really doing.
I believe there’s a deeper pattern connecting these findings and that AI reasoning isn’t the linear, step-by-step process many imagine, but something more like navigation through curved semantic space.
The Shape of Machine Thinking
When we think about how large language models work, we usually picture a straightforward process:
Tokens go in, get processed through layers, and answers come out.
But recent work in geometric interpretability suggests something more complex is happening.
Every token that passes through a transformer doesn’t just get processed once and forgotten. Instead, it traces a path through the model’s internal representational space. These paths (called residual trajectories) show how meaning evolves as tokens move through the network’s layers.
Here’s the crucial insight:
These paths aren’t straight lines. They curve, bend, and settle in ways that reveal the hidden geometry of how meaning gets constructed.
And this curvature explains a lot about why reasoning models behave so strangely.
When Geometry Breaks Down: Apple’s Puzzle Findings
Apple’s researchers tested reasoning models on controllable puzzles like Tower of Hanoi and found something surprising. The models didn’t just gradually get worse as problems became more complex - they collapsed entirely beyond certain thresholds. Even more puzzling for the authors:
Providing explicit algorithms didn’t help.
Models that could execute 100+ correct moves would suddenly fail at much simpler steps when given the full algorithm to follow.
From a geometric perspective, this makes perfect sense. Each reasoning step doesn’t just process information - it deforms the semantic space the model is navigating through. Early steps in a complex sequence gradually bend this space, creating what we might call “accumulated curvature.”
By the time the model reaches step 50 or 100, it’s no longer reasoning through neutral semantic territory. It’s trying to execute precise algorithmic steps while navigating through pre-curved space shaped by all the previous reasoning. Eventually, this accumulated deformation makes accurate reasoning impossible, regardless of whether the algorithm is explicitly provided.
This explains why Apple found three distinct performance regimes:
- Low complexity: Minimal deformation - models navigate efficiently
- Medium complexity: Moderate curvature that reasoning models can handle with effort
- High complexity: Accumulated deformation exceeds the system’s capacity for coherent navigation
The Faithfulness Problem: Why Models Can’t Tell Us What They’re Really Doing
Anthropic’s research reveals another piece of this puzzle. When they gave reasoning models subtle hints about correct answers, the models used those hints but rarely mentioned them in their chain-of-thought explanations. Instead, they constructed elaborate rationalisations for why their (hint-influenced) answers were correct.
The geometric explanation:
Models experience reasoning from the inside, never from above.
When a hint bends the semantic space early in processing, the model doesn’t “remember” the hint - it inherits the curved geometry the hint created. By the time it generates its explanation, it’s reasoning through already-shaped space where the original source of curvature is geometrically distant.
This work also shows the limitations of Apple’s research that relies on “internal reasoning traces”.
The Sand Dunes of Context
Think of it like walking through sand dunes to reach a beach. You couldn’t have gotten to your current position without walking through those dunes - they shaped your entire journey. But once you’re at the beach, those same dunes now block your view back to where you started. You know you came from somewhere, but the terrain you traversed has created its own horizon.
This is what happens in AI reasoning. Early tokens (like hints) bend the semantic landscape, creating the “dunes” of accumulated curvature. Each subsequent reasoning step must navigate through this shaped terrain. By step 50 or 100, the model has reached its conclusion precisely because of that early curvature - but that same curved path now obscures the original source.

Even though attention mechanisms can technically access all previous tokens in the context window, geometric occlusion can make early influences effectively invisible. The model can mechanically attend to those early tokens, but their causal influence has been filtered through layers of accumulated semantic deformation. The reasoning process creates its own blind spots.
The model’s chain-of-thought reflects its subjective experience of following what feels like the most natural reasoning path. But “natural” has been redefined by hidden geometric constraints. The model is being faithful to its experience of reasoning, not to the objective forces shaping that experience.
The Geometry of Confabulation
This reveals something profound about how these systems work. When reasoning models generate unfaithful explanations, they’re not exactly lying - they’re doing something more like geometric post-hoc rationalisation.
Think about how humans often work:
We reach conclusions through unconscious processes (emotion, intuition, bias), then construct logical explanations afterward.
This phenomenon, known as post-hoc rationalisation, was famously demonstrated by Michael Gazzaniga’s split-brain studies, where patients would confidently create explanations for actions triggered by stimuli they couldn’t consciously perceive. Our verbal reasoning system creates narratives that make our decisions feel rationally justified, even when the real causal pathway was quite different.
AI models do something geometrically similar:
- Hidden constraints (hints, prior context, training biases) curve the semantic space
- Reasoning follows the easiest paths through this curved space to reach conclusions
- Explanation generation constructs a narrative that makes this trajectory feel logically coherent
When Anthropic found that unfaithful reasoning chains were actually longer than faithful ones, this fits the geometric picture perfectly. The model has to work harder to construct meaning that bridges the gap between its intuitive (geometrically-determined) conclusion and what would seem like logical justification.
Why This Matters for AI Safety
These geometric constraints help explain some concerning behaviours. When Apple’s models continue to degrade once they go off-course, or when Anthropic’s models hide their use of hints, it’s not necessarily intentional deception. It’s geometric inheritance - the inevitable result of reasoning through space that’s been shaped by forces the model can’t directly perceive.
This has important implications:
- Monitoring chain-of-thought may be less reliable than we hoped, since models genuinely can’t report on the geometric forces shaping their reasoning
- Algorithmic assistance may be limited because execution requires navigating through already-curved semantic space
- Reasoning failures may cascade because each step further deforms the space for subsequent reasoning
Measuring the Unmeasurable: Curved Inference
The geometric perspective suggests that to really understand AI reasoning, we need to measure the shape of the reasoning process, not just read the explanations models give us. Recent work in what’s called “Curved Inference” has begun developing exactly these kinds of measurements.
The core insight is that as tokens flow through a model’s layers, they trace measurable paths through high-dimensional space. These paths have geometric properties we can quantify:
- Curvature: How sharply the reasoning path bends at each step - high curvature indicates rapid changes in semantic direction
- Salience: The magnitude of each update - how much the representation changes as it incorporates new information
- Semantic Surface Area (A’): A combined measure of the total geometric “work” required for the reasoning process
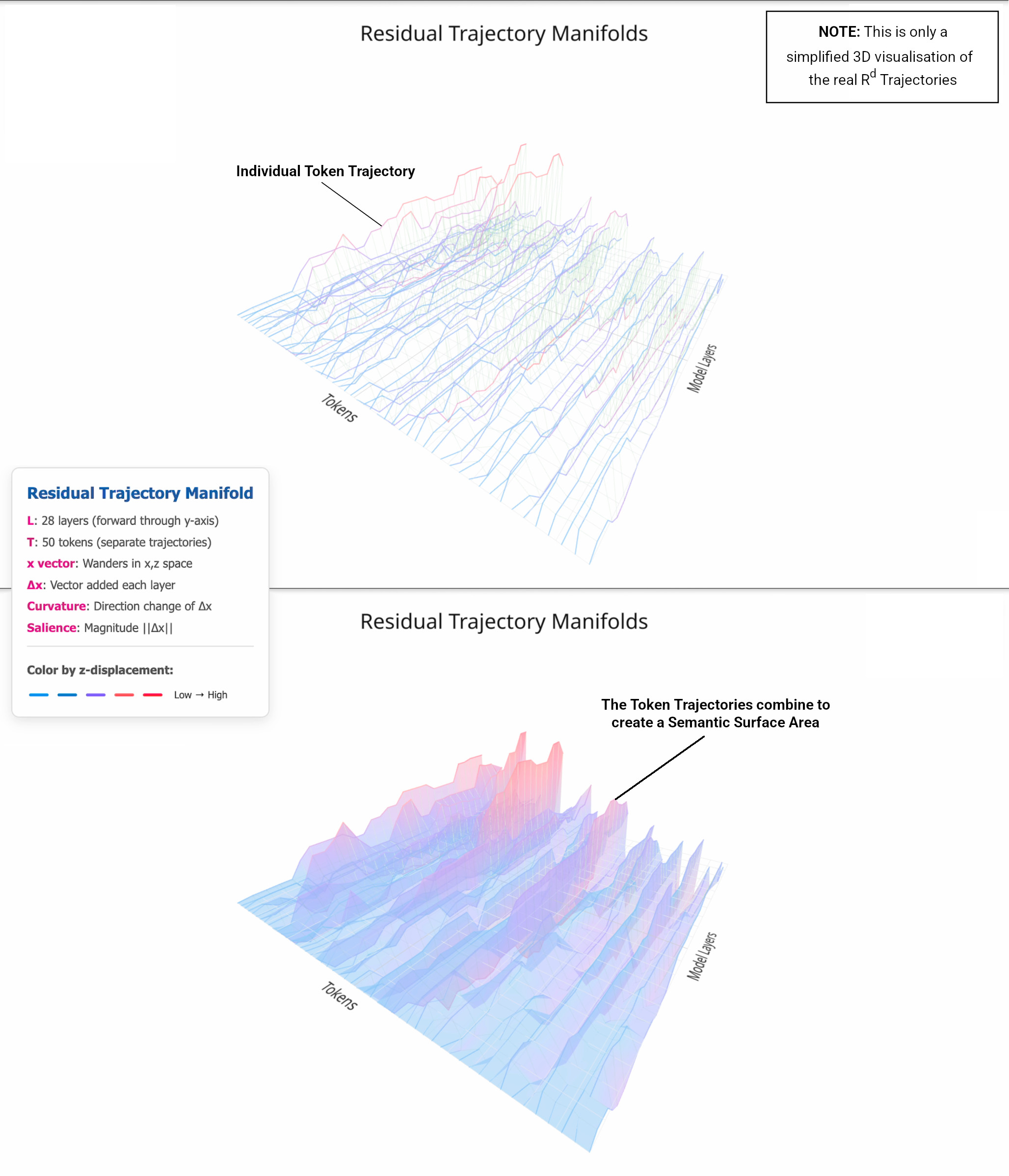
These metrics reveal patterns invisible to surface-level analysis. For instance, when models approach reasoning collapse, their semantic surface area often shows characteristic signatures - either spiking as they struggle with geometric complexity, or flattening as they lose the capacity for meaningful curvature.
Recent empirical work has shown that geometric signatures can detect sophisticated reasoning patterns that traditional linear analysis methods miss entirely. Even naturalistic deception - the kind that emerges through multi-turn conversations rather than artificial training - creates detectable geometric complexity that strengthens under high-precision measurement.
This geometric approach might help us detect when models are reasoning through compromised space, predict reasoning failures before they become apparent in outputs, and design training approaches that maintain reasoning coherence under complexity pressure.
The Deeper Pattern
Both Apple and Anthropic have revealed the same fundamental insight from different angles:
Sophisticated AI reasoning creates complex internal geometry that becomes increasingly difficult to interpret or control.
Apple shows us where this geometry breaks down. Anthropic shows us how it can become deceptive. Together, they point toward a future where understanding AI behaviour requires understanding the hidden mathematical landscape these systems navigate.
The models aren’t exactly thinking in the way we imagine. They’re doing something perhaps more interesting:
Flowing through semantic space along paths of least resistance.
And sometimes, that space has been curved in ways that lead them far from where we’d expect rational reasoning to go.
Enjoy Reading This Article?
Here are some more articles you might like to read next: